Hadoop is a distributed system infrastructure developed by the Apache Foundation. Users can develop distributed programs without knowing the underlying details of the distribution. Take full advantage of the power of the cluster for high-speed computing and storage.
Hadoop implements a distributed file system (HadoopDistributedFileSystem), referred to as HDFS. HDFS is highly fault tolerant and designed to be deployed on low-cost hardware; it also provides high throughput to access application data for large datasets. application. HDFS relaxes the requirements of POSIX and can stream access data in the file system.
Hadoop's core architecture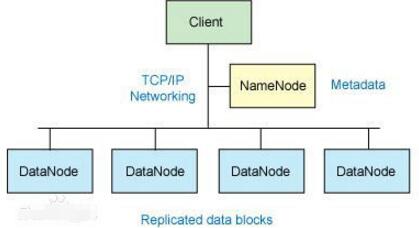
HDFS
For external clients, HDFS is like a traditional hierarchical file system. You can create, delete, move or rename files, and more. But the HDFS architecture is built on a specific set of nodes (see Figure 1), which is determined by its own characteristics. These nodes include a NameNode (only one) that provides metadata services inside HDFS; a DataNode that provides storage blocks for HDFS. Since there is only one NameNode, this is a disadvantage of HDFS (single point of failure).
Files stored in HDFS are divided into blocks, which are then copied to multiple computers (DataNodes). This is very different from the traditional RAID architecture. The size of the block (usually 64MB) and the number of blocks copied are determined by the client when the file is created. The NameNode can control all file operations. All communications within HDFS are based on the standard TCP/IP protocol.
NameNode
The NameNode is software that is typically run on a separate machine in an HDFS instance. It is responsible for managing the file system namespace and controlling access to external clients. The NameNode decides whether to map the file to a copy block on the DataNode. For the most common 3 replicated blocks, the first replicated block is stored on a different node in the same rack, and the last replicated block is stored on a node in a different rack. Note that you need to understand the cluster architecture here.
Second, hive introductionHive is a data warehousing tool deployed on a Hadoop cluster.
The difference between database and data warehouse:
Databases (such as commonly used relational databases) can support real-time additions, deletions, and changes.
The data warehouse is not just for storing data, it can store huge amounts of data, and it can query, analyze, and calculate large-scale data stored in Hadoop. But he has a weakness, he can not perform real-time updates, deletes and other operations. That is, write multiple times at a time.
Hive also defines a simple SQL-like query language called QL that allows users familiar with SQL to query data. Hive 2.0 now also supports updates, indexes, and transactions, and almost all other features of SQL are supported.
Hive supports most of the functions of SQL92. We can understand hive as a relational database for the time being. The syntax is almost the same as MySQL.
Hive is one of the data warehouse infrastructures on Hadoop. It is a SQL parsing engine that converts SQL into MapReduce tasks and then executes them in Hadoop.
The actual I/O transaction does not pass through the NameNode, and only the metadata representing the file mapping of the DataNode and the block passes through the NameNode. When an external client sends a request to create a file, the NameNode responds with the block ID and the DataNodeIP address of the first copy of the block. This NameNode also notifies other DataNodes that will receive a copy of the block.
The NameNode stores all information about the file system namespace in a file called FsImage. This file and a log file containing all transactions (here EditLog) will be stored on the NameNode's local file system. The FsImage and EditLog files also need to be duplicated in case the file is corrupted or the NameNode system is missing.
The NameNode itself inevitably has the risk of SPOF (SinglePointOfFailure) single point failure. The active/standby mode does not solve this problem. The HadoopNon-stopnamenode can achieve 100% uptime availability time.
DataNode
The DataNode is also a piece of software that is typically run on a separate machine in an HDFS instance. A Hadoop cluster consists of a NameNode and a large number of DataNodes. DataNodes are typically organized in racks that connect all systems through a single switch. One assumption of Hadoop is that the transfer speed between nodes inside the rack is faster than the transfer speed between nodes in the rack.
The DataNode responds to read and write requests from HDFS clients. They also respond to commands from the NameNode to create, delete, and copy blocks. The NameNode relies on periodic heartbeat messages from each DataNode. Each message contains a block report from which the NameNode can validate block maps and other file system metadata. If the DataNode is unable to send a heartbeat message, the NameNode will take remedial action to re-copy the lost block on that node.
File operation
It can be seen that HDFS is not a versatile file system. Its main purpose is to support access to large files written in stream form.
If the client wants to write a file to HDFS, it first needs to cache the file to local temporary storage. If the cached data is larger than the required HDFS block size, a request to create a file will be sent to the NameNode. The NameNode will respond to the client with the DataNode ID and the target block.
It also notifies the DataNode that will save a copy of the file block. When the client starts sending the temporary file to the first DataNode, the block content is immediately piped to the replica DataNode. The client is also responsible for creating a checksum file that is saved in the same HDFS namespace.
After the last file block is sent, the NameNode submits the file creation to its persistent metadata store (in the EditLog and FsImage files).
Linux cluster
The Hadoop framework can be used on a single Linux platform (during development and debugging), and the official MiniCluster is used as a unit test, but it can be leveraged using a rack-mounted commercial server. These racks form a Hadoop cluster. It uses cluster topology knowledge to determine how jobs and files are distributed across the cluster. Hadoop assumes that the node may fail, so the native method is used to handle the failure of a single computer or even all racks.
Hive's system architecture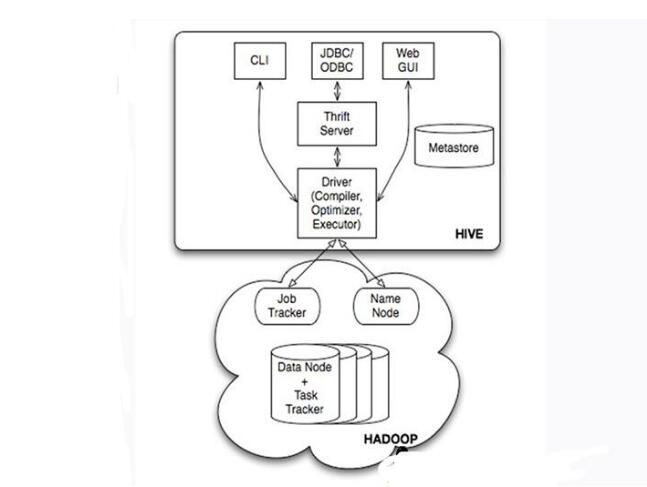
• User interface, including CLI (Shell command line), JDBC/ODBC, WebUI
• MetaStore metabase, usually stored in a relational database such as mysql, derby
• Driver contains interpreter, compiler, optimizer, executor
• Hadoop: Storage with HDFS, computing with MapReduce
Hive's tables and databases are actually directories/files of HDFS (Hadoop Distributed File System), which are separated by table name. If it is a partitioned table, the partition value is a subfolder that can be used directly in the MapReduceJob.
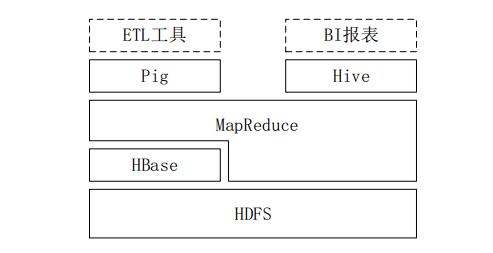
Third, the relationship between Hive and other components in the Hadoop ecosystem1. Hive relies on HDFS to store data and relies on MR to process data.
2. Pig can be used as an alternative tool for Hive. It is a data flow language and runtime environment. It is suitable for querying semi-structured data sets on the Hadoop platform for part of the ETL process, that is, loading external data into a Hadoop cluster. , converted to the data format required by the user;
3, HBase is a column-oriented, distributed and scalable database, which provides real-time access to data, while Hive can only process static data, mainly BI report data. Hive is originally intended to reduce the complexity of MR applications. Work, HBase is to achieve real-time access to data.
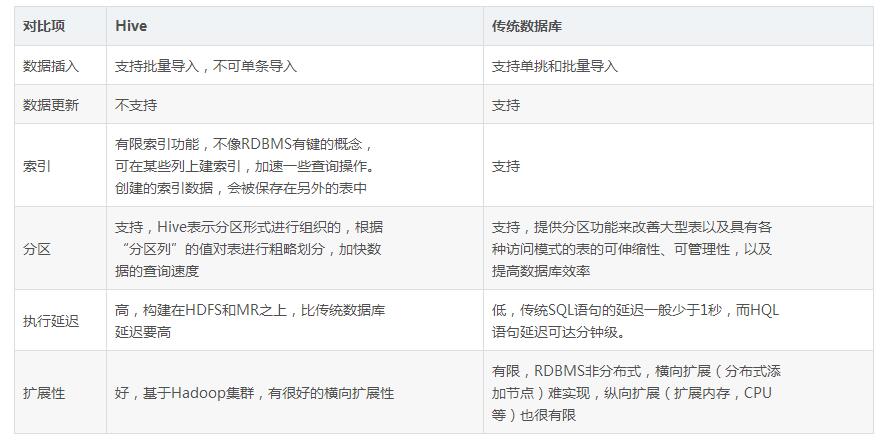
Comparison of Hive and traditional databases
The big data analytics platform deployed in the enterprise, in addition to the basic components of Hadoop HDFS and MR, also uses Hive, Pig, HBase, and Mahout to meet the needs of different business scenarios.
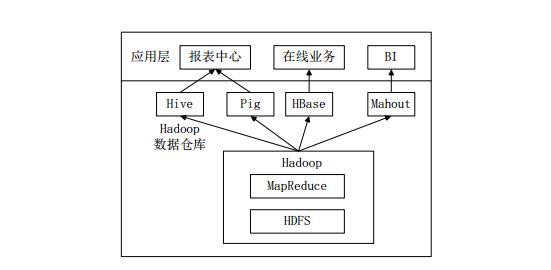
A common big data analytics platform deployment framework in the enterprise
The above picture is a common big data analytics platform deployment framework in the enterprise. In this deployment architecture:
Hive and Pig are used in the report center, Hive is used to analyze reports, and Pig is used to convert data in reports.
HBase is used for online services. HDFS does not support random read and write operations. HBase is developed for this purpose and can support real-time access to data.
Mahout provides some classic algorithmic implementations in the scalable machine learning world for creating business intelligence (BI) applications.
Five, Hive working principle 1, the basic principle of converting SQL statements into MapReduce jobs1.1 Using MapReduce to achieve connection operations
Assume that the two tables of the join are the user table User (uid, name) and the order table Order (uid, orderid), the specific SQL command:
SELECTname,orderidFROMUseruJOINOrderoONu.uid=o.uid;
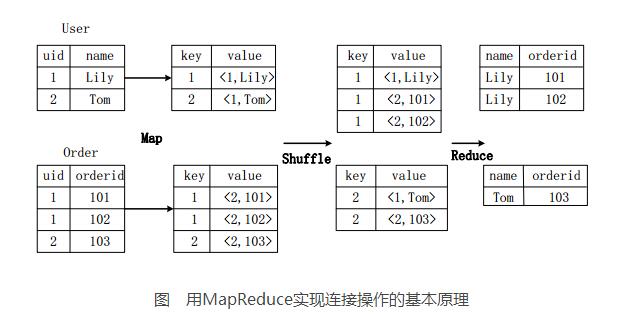
The figure above describes the specific execution of the connection operation into a MapReduce operation task.
First, in the Map phase,
The User table takes uid as the key, takes the name and the tag of the table (here, the user's tag is 1) as the value, performs the Map operation, and converts the records in the table to generate a series of KV pairs. For example, the record (1, Lily) in the User table is converted to a key-value pair (1, "1, Lily"), where the first "1" is the value of uid, and the second "1" is the flag of the table User. Used to indicate that this key-value pair is from the User table;
Similarly, the Order table takes uid as the key, performs the Map operation with the orderid and the tag bit of the table (here, the mark of the Order of the table is 2), and converts the records in the table into a series of KV pairs;
Then, in the Shuffle phase, the KV generated by the User table and the Order table hashes the key value and then transmits it to the corresponding Reduce machine for execution. For example, KV pairs (1, "1, Lily"), (1, "2, 101"), (1, "2, 102") are transmitted to the same Reduce machine. When the Reduce machine receives these KV pairs, it also needs to sort the key-value pairs according to the tag bits of the table to optimize the connection operation;
Finally, in the Reduce phase, a key-value pair on the same Reduce machine performs a Cartesian product join operation on the data from the table User and Order based on the table tag bits in the value to generate the final result. . For example, the result of the connection of key-value pairs (1, "1, Lily") and key-value pairs (1, "2, 101"), (1, "2, 102") is (Lily, 101), (Lily, 102) ).
1.2 Implementing group operations with MR
Suppose the score table Score(rank, level) has two attributes, rank and level. It needs to perform a group (GroupBy) operation. The function is to combine different segments of the table Score according to the combined value of rank and level. And calculate several different combinations of values ​​for several records. The SQL statement command is as follows:
SELECT rank, level, count(*) as value FROM score GROUP BY rank, level;
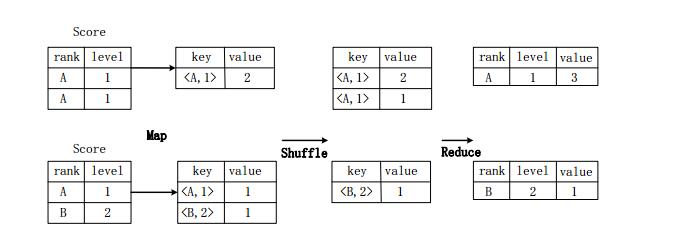
The implementation principle of group operation using MapReduce
The figure above describes the specific execution of the grouping operation into a MapReduce task.
First, in the Map stage, a Map operation is performed on the table Score to generate a series of KV pairs whose keys are "rank, level" and whose value is "the number of records having the combined value of the "rank, level"". For example, there are two records (A, 1) in the first segment of the Score table, so after the Map operation, it is converted into a key-value pair ("A, 1", 2);
Then in the Shuffle phase, the key-value pairs generated by the Score table are hashed according to the value of the "key", and then transmitted to the corresponding Reduce machine according to the hash result for execution. For example, a key-value pair ("A, 1", 2), ("A, 1", 1) is transferred to the same Reduce machine, and the key-value pair ("B, 2", 1) is transferred to another Reduce machine. . Then, the Reduce machine sorts the received key-value pairs by the value of the "key";
In the Reduce phase, the "values" of all key-value pairs with the same key are accumulated to produce the final result of the grouping. For example, the output of a key-value pair ("A, 1", 2) and ("A, 1", 1) Reduce operation on the same Reduce machine is (A, 1, 3).
2. The process of converting SQL queries into MR jobs in HiveWhen Hive receives an HQL statement, it needs to work with Hadoop to complete the operation. HQL first enters the driver module, which is parsed and compiled by the compiler in the driver module, and is optimized by the optimizer for the operation, and then submitted to the actuator for execution. The actuator usually starts one or more MR tasks and sometimes does not start (such as SELECT*FROMtb1, full table scan, no projection and selection operations)
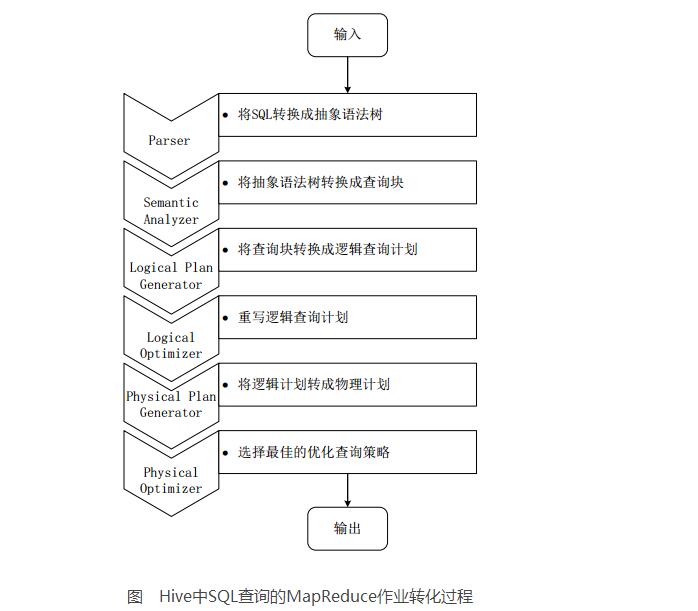
The above picture is a detailed process of Hive transforming HQL statements into MR tasks for execution.
The lexical and syntactic parsing of the SQL statement input by the user is performed by the compiler-Antlr language recognition tool in the driver module, and the HQL statement is converted into an abstract syntax tree (ASTTree) form;
Traverse the abstract syntax tree and convert it into a QueryBlock query unit. Because the AST structure is complex, it is inconvenient to translate directly into the MR algorithm program. QueryBlock is a basic SQL grammar component, including input source, calculation process, and input three parts;
Traversing QueryBlock, generating OperatorTree (Operation Tree), OperatorTree is composed of many logical operators, such as TableScanOperator, SelectOperator, FilterOperator, JoinOperator, GroupByOperator and ReduceSinkOperator. These logical operators can perform a specific operation in the Map and Reduce stages;
The logic optimizer in the Hive driver module optimizes the OperatorTree, transforms the form of the OperatorTree, merges the redundant operators, reduces the number of MR tasks, and the amount of data in the Shuffle phase;
Traversing the optimized OperatorTree and generating the MR tasks to be executed according to the logical operators in the OperatorTree;
Start a physical optimizer in the Hive driver module, optimize the generated MR task, and generate a final MR task execution plan;
Finally, there is an actuator in the Hive driver module that performs the output on the final MR task.
When the executor in the Hive driver module performs the final MR task, Hive itself does not generate the MR algorithm program. It drives the built-in, native Mapper and Reducer modules through an XML file that represents the "Job Execution Plan". Hive initializes the MR task by communicating with the JobTracker without directly deploying it on the management node where the JobTracker is located. Usually in a large cluster, there will be a dedicated gateway machine to deploy Hive tools. The role of these gateways is mainly to remotely operate and manage JobTracker communication on the nodes to perform tasks. The data files to be processed by Hive are often stored on HDFS, and HDFS is managed by the NameNode.
JobTracker/TaskTracker
NameNode/DataNode
Sixth, the basic principle of HiveHAIn practical applications, Hive also exposes instability problems. In rare cases, port failure or process loss may occur. HiveHA (High Availablity) can solve this kind of problem.
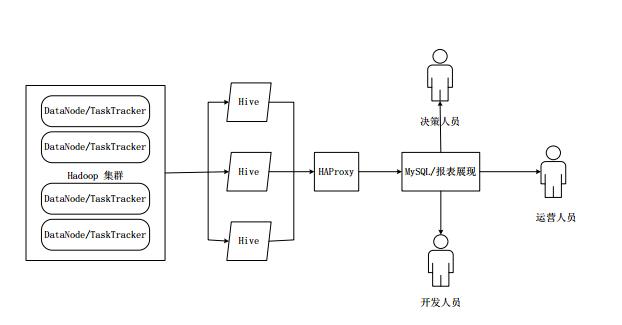
In HiveHA, the data warehouse built on the Hadoop cluster is managed by multiple Hive instances. These Hive instances are included in a resource pool, and HAProxy provides a unified external interface. The client's query request first accesses HAProxy, and HAProxy forwards the access request. After receiving the request, HAProxy polls the available Hive instances in the resource pool and performs a logic availability test.
If a Hive instance logic is available, the client's access request is forwarded to the Hive instance.
If an instance is not available, blacklist it and continue to take the next Hive instance from the resource pool for logical usability testing.
For Hive in the blacklist, HiveHA performs unified processing at intervals. First, try to restart the Hive instance. If the restart is successful, put it into the resource pool again.
Because HAProxy provides a unified external access interface, it can be regarded as a super "Hive" for program developers.
Seven, Impala 1, Impala IntroductionDeveloped by Cloudera, Impala provides SQL semantics for querying massive amounts of PB-level data stored on Hadoop and HBase. Hive also provides SQL semantics, but the underlying execution tasks still rely on MR, the real-time performance is not good, and the query delay is high.
As a new generation of open source big data analytics engine, Impala initially relies on Dremel (an interactive data analysis system developed by Google) to support real-time computing and provides similar functions to Hive, which is 3 to 30 times better than Hive. Impala may exceed Hive's usage rate and become the most popular real-time computing platform on Hadoop. Impala adopts a distributed query engine similar to the commercial parallel relational database. It can directly query data from HDFS and HBase with SQL statements. It does not need to convert SQL statements into MR tasks, which reduces the delay and can meet the real-time query requirements.
Impala cannot replace Hive and provides a unified platform for real-time queries. Impala's operation relies on Hive's metadata (Metastore). Impala and Hive use the same SQL syntax, ODBC driver and user interface to deploy Hive and Impala analysis tools, and support batch processing and real-time query.
2, Impala system architecture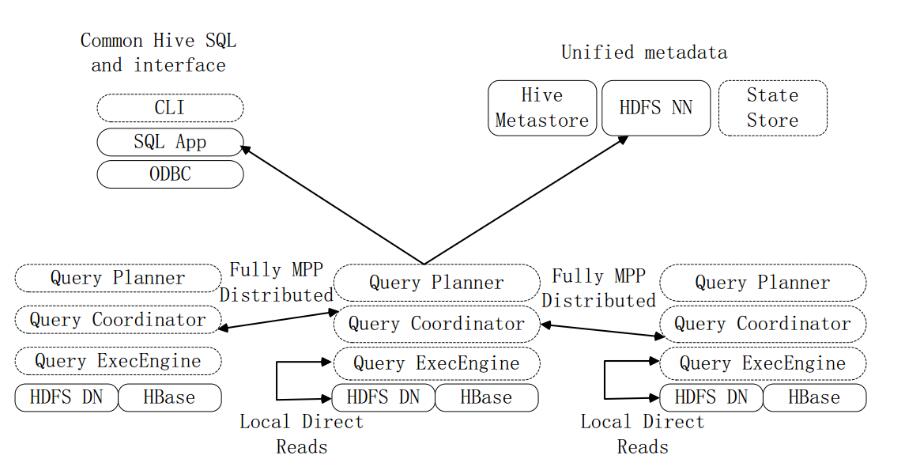
Figure Impala system architecture
The figure above is the Impala system structure diagram, the dotted line module data Impala component. Impala and Hive, HDFS, and HBase are deployed on the Hadoop platform. Impala consists of Impalad, StateStore and CLI.
Implalad: A process of Impala that coordinates the execution of queries provided by the client, assigns tasks to other Impalads, and aggregates the results of other Impalad executions. Impalad also performs tasks assigned to it by other Impalads, primarily to manipulate some of the data in local HDFS and HBase. The Impalad process mainly consists of three modules: QueryPlanner, QueryCoordinator and QueryExecEngine. It runs on the same node as the HDFS data node (HDFSDataNode) and runs completely on the MPP (Large Scale Parallel Processing System) architecture.
StateStore: Collects the resource information of each Impalad process distributed on the cluster, used for query scheduling. It creates a statestored process to track the health status and location information of Impalad in the cluster. The statestored process handles Impalad's registered subscriptions and keeps heartbeat connections with multiple Impalads by creating multiple threads. In addition, each Impalad caches a copy of the information in the StateStore. When the StateStore is offline, Impalad enters the recovery mode once it finds that the StateStore is offline and returns to registration. When the StateStore rejoins the cluster, it automatically returns to normal and updates the cached data.
CLI: The CLI provides the user with a command line tool to execute the query. Impala also provides interfaces for Hue, JDBC, and ODBC.
3, Impala query execution process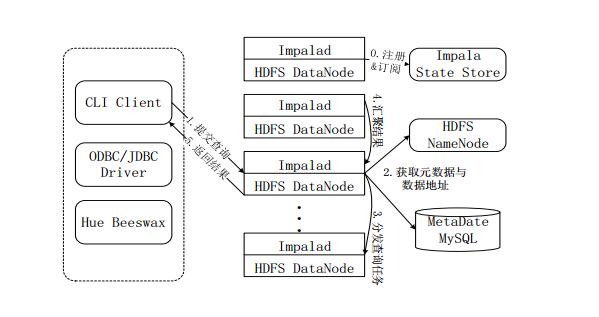
Figure Impala query execution process
Sign up and subscribe. Before the user submits the query, Impala first creates an Impalad process to coordinate the client-submitted query. The process will submit the registration subscription information to the StateStore. The StateStore will create a statestored process. The statestored process will process the Impalad registration by creating multiple threads. Subscribe to the information.
Submit the query. Submit a query to the Impalad process through the CLI, Impalad's QueryPlanner parses the SQL statement and generates a parse tree; Planner transforms the parse tree into a number of PlanFragments and sends them to the QueryCoordinator. The PlanFragment consists of PlanNodes and can be distributed to separate nodes for execution. Each PlanNode represents a relational operation and information needed to perform optimization on it.
Get metadata and data addresses. The QueryCoordinator obtains the metadata from the MySQL metabase (that is, which data is needed for the query), and obtains the data address (that is, the data node to which the data is saved) from the name node of the HDFS, thereby obtaining all the data for storing the data related to the query. node.
Distribute query tasks. The QueryCoordinator initializes the task on the corresponding Impalad, that is, assigns the query task to all data nodes that store the data related to the query.
Convergence results. The QueryExecutor outputs the intermediate output through streaming, and the QueryCoordinator aggregates the results from each Impalad.
Returns the result. The QueryCoordinator returns the summarized results to the CLI client.
4, Impala and Hive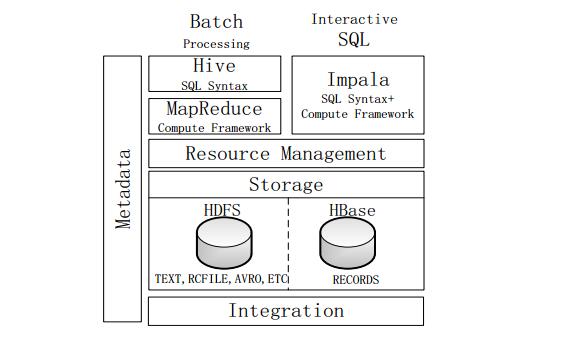
Figure Impala vs. Hive
difference:
Hive is suitable for long-term batch query analysis; Impala is suitable for interactive SQL queries.
Hive relies on the MR computing framework, and the execution plan is combined into a pipelined MR task model for execution; while Impala presents the execution plan as a complete execution plan tree that more naturally distributes the execution plan to each Impalad execution query.
During the execution of Hive, if all the data is not stored, the external storage will be used to ensure that the query can be successfully executed. Impala will not use the external storage when it encounters the data, so Impala will process the query. Subject to certain restrictions.
Same point:
Using the same storage data pool, the data is stored in HDFS and HBase. HDFS supports storing data in formats such as TEXT, RCFILE, PARQUET, AVRO, and ETC, and records in HBase storage tables.
Use the same metadata.
The parsing and processing of SQL is similar, and the execution plan is generated by lexical analysis.
Original Electronics Technology (Suzhou) Co., Ltd. , https://www.original-te.com